
숟가락 그만 얹어
Deep Infomax 본문
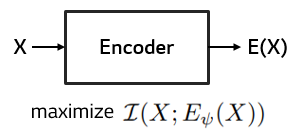
Contribution
1. MINE [2]을 이용하여 X와 E(X)의 mutual information을 maximize하여 downstream task에 적합한 representation을 생성
2. X를 여러 개의 local patch로 나누고 E(X)와의 average mutual information을 maximize하여 pixel 단위의 noise를 제거한 representation 생성
3. Desirable statistical properties (compact, indepedent, disentagled)를 달성하기 위해 adversarial training을 이용하여 prior에 fitting
References
[1] R. D. Hjelm et al., Learning Deep Representations by Mutual Information Estimation and Maximization, ICLR 2019
[2] M. I. Belghzi et al., Mutual Information Neural Estimation, ICML 2018
'Research > Representations' 카테고리의 다른 글
| PCA (Principal Component Analysis) (0) | 2022.02.28 |
|---|---|
| ANICA (0) | 2020.12.20 |
| Information Bottleneck (0) | 2020.12.19 |
| MINE (0) | 2020.12.19 |
| VAE + Regression (0) | 2020.08.01 |
'Research/Representations' Related Articles
more



