
숟가락 그만 얹어
Time-series Anomaly Detection by PCA (1) 본문
데이터의 특성에 따라 anomaly detection, predictive maintenace, fault detection, one-class classification 등으로 불리는 이 문제는 정상 데이터만으로 모델링을 수행하고, 통계적 threshold를 설정하여 비정상 outlier를 검출하는 것이다. PCA로 모델링을 하면 특정 time t에서 센서 간의 관계성은 잘 반영하지만 (cross-correlation), 시간적인 변화 특성은 반영하지 못한다 (auto-correlation). 직접 실험을 해보면 이상 패턴이 연속적으로 여러 시간에 걸쳐서 나타나는 경우에는 PCA가 그리 효과가 없다. 이를 해결하기 위해 Dynamic PCA, CVA 같은 method는 covariance 계산 시 센서 간의 time lag을 두어 시간 변화 특성을 반영하도록 강제하는데, time lag 선택에 종속되다보니 근본적인 해결책은 아닌 듯 하다. 차라리 spatiotemporal covariance를 계산하여 모델링을 해보면 어떨까? 아직 이런 연구를 찾지는 못했다.
정상 데이터로만 PCA 후 주성분과 주성분이 아닌 부분을 적당히 나누어주고 실제 검증할 데이터에 대해 차원 변환을 수행한다. 원 데이터에 대해 1) 주성분 vector로 변환하면 아래 그림에서 타원 공간 내에 위치하게 된다. 2) 주성분이 아닌 vector로 변환하면 타원 바깥 공간에 위치하게 된다.
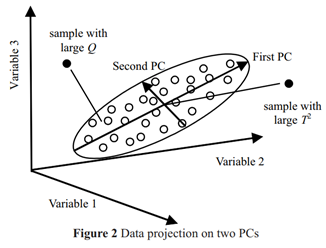
주성분 벡터로 변환된 데이터가 타원 공간 내에서 중심으로 부터 거리가 멀리 떨어져 있거나 (T^2), 주성분이 아닌 벡터로 변환된 데이터가 타원으로부터 멀리 떨어져 있을 때 (SPE) anomaly로 검출한다. 위 과정은 다음과 같이 정리할 수 있다.

이 때, T^2은 Mahalanobis distance이기 때문에 Hotelling's T^2 distribution을 따른다고 한다. 이 분포는 F distribution을 상수배 한 것인데, distance를 eigenvalue로 나누어주었기 때문에 단순히 Chi-square distribution을 쓰지 않은 것 같다. SPE는 multi-normal distribution을 따른다고 가정하고 critical value를 구하려고 한다면 아래와 같은 수식으로 approximation 될 수 있다고 한다.

References
[1] S. Yin et al., A comparison study of basic data-driven fault diagnosis and process monitoring methods on the benchmark Tennessee Eastman Process, J. Process Control, 2012
[2] T. Heo et al., Development of Real-Time Water Quality Abnormality Warning System for Using Multivariate Statistical Method., J. Korean Soc, 2015
'Research > Anomaly Detection' 카테고리의 다른 글
| Deep SAD (0) | 2020.09.14 |
|---|---|
| Classification-based Anomaly Detection (0) | 2020.09.10 |
| MSCRED (0) | 2020.08.29 |
| Time-series Anomaly Detection by PCA (3) (0) | 2020.07.15 |
| Time-series Anomaly Detection by PCA (2) (0) | 2020.07.15 |



