Research/Generative Model
Relative Position Representations
업무외시간
2021. 3. 12. 18:29
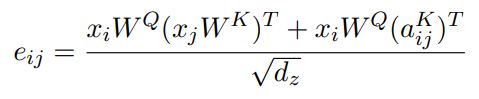
Efficient implementation을 위해 위 식을 tensor 형태로 표현하면
Key : (batch_size, head, seq_length, d)
Query : (batch_size, head, seq_length, d)
A : (seq_length, seq_length, d)
Tensor A는 embedding (i, j)의 learnable position distance 정보를 담고 있음. i와 j의 relative distance가 일정 이상 (k) 멀어지면 clip하여 설정한 index k 또는 -k의 embedding이 사용되도록 설계함.
Query * Key : (batch, head, seq_length, seq_length)
Query * A : (batch_size, head, seq_length, seq_length)
E : (batch_size, head, seq_length, seq_length)
References
[1] P. Shaw et al., Self-Attention with Relative Position Representations, arXiv 2018
[2] medium.com/@_init_/how-self-attention-with-relative-position-representations-works-28173b8c245a